Kolab Deployment on Multiple Servers¶
This deployment scenario spreads components over multiple servers for the purpose of load-balancing, implicitly including a level of high-availability.
Each functional component in Kolab Groupware can be scaled up, and scaled down, independent from the other components.
A single server deployment provides the following services:
LDAP
MTA
Storage
IMAP
Web Client Interfaces
These services can be spread out over multiple systems:
![digraph {
"Web Server" -> "IMAP Server", "LDAP Server", "MTA Server", "Database Server" [dir=none];
"IMAP Server" -> "LDAP Server", "Storage Server" [dir=none];
"MTA Server" -> "LDAP Server" [dir=none];
}](../_images/graphviz-996a4632e8fcfb4f63b6f9cd4d80445049c97611.png)
Multiple Servers with Multiple Services Each¶
Alternatively, some services can run on one server, while other services run on another:
![digraph {
subgraph cluster_1 {
label="Kolab Server #1";
"Web", "Database", "MTA";
}
subgraph cluster_2 {
label="Kolab Server #2";
"IMAP", "LDAP", "Storage";
}
"Web" -> "IMAP", "LDAP", "MTA", "Database" [dir=none];
"IMAP" -> "LDAP", "Storage" [dir=none];
"MTA" -> "LDAP" [dir=none];
}](../_images/graphviz-6dbfe15288103748769e57465c5dc448033f8b40.png)
Multiple Servers for Each Service¶
Services can also be spread out even more, and duplicated for extra processing power, load-balacing, redundancy and/or high-availability:
![digraph {
subgraph cluster_1 {
label="Web Cluster";
"Web #1", "Web #2";
}
subgraph cluster_2 {
label="Database Cluster";
"Database #1", "Database #2";
}
subgraph cluster_3 {
label="MTA Cluster";
"MTA #1", "MTA #2";
}
subgraph cluster_4 {
label="LDAP Cluster";
"LDAP #1", "LDAP #2";
}
subgraph cluster_5 {
label="IMAP Cluster";
"IMAP #1", "IMAP #2";
}
subgraph cluster_6 {
label="Storage Cluster";
"Storage #1", "Storage #2";
}
"Web #1", "Web #2" -> "Database #1", "Database #2" [dir=none];
"Web #1", "Web #2" -> "MTA #1", "MTA #2" [dir=none];
"Web #1", "Web #2" -> "LDAP #1", "LDAP #2" [dir=none];
"Web #1", "Web #2" -> "IMAP #1", "IMAP #2" [dir=none];
"IMAP #1", "IMAP #2" -> "LDAP #1", "LDAP #2" [dir=none];
"IMAP #1", "IMAP #2" -> "Storage #1", "Storage #2" [dir=none];
"MTA #1", "MTA #2" -> "LDAP #1", "LDAP #2" [dir=none];
}](../_images/graphviz-cced223d44124a2f9eb65c123783b1aaa2153461.png)
While the Introduction chapter in the Architecture & Design document included a high-level overview of functional components, in this chapter we can zoom in a little and define the functional components by a role. Generically speaking this would include the following roles:
LDAP
(write) master
(read) slave
(read) proxy
See also
deployment-multi-server-ldap-replication
Web services
Application
Asset
Proxy
See also
deployment-multi-server-web-services
Data Storage Layer
Databases
(write) master
(read) slave
Mail Exchangers
Anti-Spam and Anti-Virus (AS/AV)
Backend Mail Exchanger
External Mail Exchanger (inbound)
External Mail Exchanger (outbound)
Internal Mail Exchanger
Submission Mail Exchanger
See also
deployment-multi-server-mail-exchangers
To illustrate how this could look like we put it into a diagram:
![digraph {
splines = true;
overlab = prism;
edge [color=gray50, fontname=Calibri, fontsize=11];
node [style=filled, shape=record, fontname=Calibri, fontsize=11];
subgraph cluster_db {
color = "white";
style = "filled";
subgraph cluster_dbw {
color = "white";
style = "filled";
"Database";
}
}
subgraph cluster_imap {
color = "white";
style = "filled";
subgraph cluster_imapb {
color = "white";
style = "filled";
"IMAP Backend";
}
subgraph cluster_imapf {
color = "white";
style = "filled";
"IMAP Frontend";
}
subgraph cluster_imapp {
color = "white";
style = "filled";
"IMAP Proxy";
}
}
subgraph cluster_ldap {
color = "white";
style = "filled";
subgraph cluster_ldapw {
color = "white";
style = "filled";
"LDAP Master";
}
subgraph cluster_ldapr {
color = "white";
style = "filled";
"LDAP Slave";
}
subgraph cluster_ldapp {
color = "white";
style = "filled";
"LDAP Proxy";
}
}
subgraph cluster_memc {
color = "white";
style = "filled";
"Memcached";
}
subgraph cluster_mx {
color = "white";
style = "filled";
subgraph cluster_as {
color = "white";
style = "filled";
"AS/AV";
}
subgraph cluster_emi {
color = "white";
style = "filled";
"Ext. MX (in)";
}
subgraph cluster_emo {
color = "white";
style = "filled";
"Ext. MX (out)";
}
subgraph cluster_im {
color = "white";
style = "filled";
"Int. MX";
}
}
subgraph cluster_web {
color = "white";
style = "filled";
subgraph cluster_web1 {
color = "white";
style = "filled";
"Webmail";
}
subgraph cluster_web2 {
color = "white";
style = "filled";
"ActiveSync";
}
subgraph cluster_weba {
color = "white";
style = "filled";
"Web Asset";
}
subgraph cluster_webp {
color = "white";
style = "filled";
"Web Proxy";
}
}
"External SMTP Servers" [color="#FFEEEE"];
"LDAP Master" -> "LDAP Slave" [dir=one];
"LDAP Slave" -> "LDAP Proxy" [dir=back];
"External SMTP Servers" -> "Ext. MX (in)";
"Ext. MX (in)" -> "LDAP Proxy";
"Ext. MX (in)" -> "AS/AV" [dir=both];
"Int. MX" -> "LDAP Proxy";
"Int. MX" -> "IMAP Backend";
"Int. MX" -> "Ext. MX (out)";
"Int. MX" -> "Ext. MX (in)" [dir=back];
"Ext. MX (out)" -> "External SMTP Servers";
"Web Proxy" -> "Webmail";
"Web Proxy" -> "ActiveSync";
"Webmail" -> "LDAP Proxy";
"Webmail" -> "Int. MX";
"Webmail" -> "Memcached" [dir=none];
"Webmail" -> "Database";
"Webmail" -> "IMAP Frontend";
"ActiveSync" -> "LDAP Proxy";
"ActiveSync" -> "Int. MX";
"ActiveSync" -> "Memcached" [dir=none];
"ActiveSync" -> "Database";
"ActiveSync" -> "IMAP Frontend";
"IMAP Proxy" -> "IMAP Frontend" [dir=none];
"IMAP Frontend" -> "IMAP Backend" [dir=none];
"Client (External)" -> "Ext. MX (in)";
"Client (External)" -> "IMAP Proxy";
"Client (External)" -> "Web Asset";
"Client (External)" -> "Web Proxy";
"IMAP Frontend" -> "Client (Internal)" [dir=back];
"Int. MX" -> "Client (Internal)" [dir=back];
"Web Asset" -> "Client (Internal)" [dir=back];
"Web Proxy" -> "Client (Internal)" [dir=back];
}](../_images/graphviz-031a3f0c94ae71a4f309cc65d42e819a38fc8a25.png)
![digraph {
splines = true;
overlab = prism;
edge [color=gray50, fontname=Calibri, fontsize=11];
node [style=filled, shape=record, fontname=Calibri, fontsize=11];
subgraph cluster_db {
color = "white";
style = "filled";
subgraph cluster_dbw {
color = "white";
style = "filled";
"DB Master #1";
"DB Master #2";
}
subgraph cluster_dbr {
color = "white";
style = "filled";
"DB Slave #1";
"DB Slave #2";
}
}
subgraph cluster_imap {
color = "white";
style = "filled";
subgraph cluster_imapb {
color = "white";
style = "filled";
"IMAP Backend #1";
"IMAP Backend #2";
}
subgraph cluster_imapf {
color = "white";
style = "filled";
"IMAP Frontend #1";
"IMAP Frontend #2";
}
subgraph cluster_imapp {
color = "white";
style = "filled";
"IMAP Proxy #1";
"IMAP Proxy #2";
}
}
subgraph cluster_ldap {
color = "white";
style = "filled";
subgraph cluster_ldapw {
color = "white";
style = "filled";
"LDAP Master #1";
"LDAP Master #2";
}
subgraph cluster_ldapr {
color = "white";
style = "filled";
"LDAP Slave #1";
"LDAP Slave #2";
}
subgraph cluster_ldapp {
color = "white";
style = "filled";
"LDAP Proxy #1";
"LDAP Proxy #2";
}
}
subgraph cluster_memc {
color = "white";
style = "filled";
"Memcached #1";
"Memcached #2";
}
subgraph cluster_mx {
color = "white";
style = "filled";
subgraph cluster_as {
color = "white";
style = "filled";
"AS/AV #1";
"AS/AV #2";
}
subgraph cluster_emi {
color = "white";
style = "filled";
"Ext. MX (in) #1";
"Ext. MX (in) #2";
}
subgraph cluster_emo {
color = "white";
style = "filled";
"Ext. MX (out) #1";
"Ext. MX (out) #2";
}
subgraph cluster_im {
color = "white";
style = "filled";
"Int. MX #1";
"Int. MX #2";
}
}
subgraph cluster_web {
color = "white";
style = "filled";
subgraph cluster_web1 {
color = "white";
style = "filled";
"Webmail #1";
"Webmail #2";
}
subgraph cluster_web2 {
color = "white";
style = "filled";
"ActiveSync #1";
"ActiveSync #2";
}
subgraph cluster_weba {
color = "white";
style = "filled";
"Web Asset #1";
"Web Asset #2";
}
subgraph cluster_webp {
color = "white";
style = "filled";
"Web Proxy #1";
"Web Proxy #2";
}
}
"External SMTP Servers" [color="#FFEEEE"];
"LDAP Master #1", "LDAP Master #2" -> "LDAP Slave #1", "LDAP Slave #2" [dir=one];
"LDAP Slave #1", "LDAP Slave #2" -> "LDAP Proxy #1", "LDAP Proxy #2" [dir=back];
"External SMTP Servers" -> "Ext. MX (in) #1", "Ext. MX (in) #2";
"Ext. MX (in) #1", "Ext. MX (in) #2" -> "LDAP Proxy #1", "LDAP Proxy #2";
"Ext. MX (in) #1", "Ext. MX (in) #2" -> "AS/AV #1" [dir=both];
"Ext. MX (in) #1", "Ext. MX (in) #2" -> "AS/AV #2" [dir=both];
"Ext. MX (in) #1", "Ext. MX (in) #2" -> "Int. MX #1", "Int. MX #2";
"Int. MX #1", "Int. MX #2" -> "LDAP Proxy #1", "LDAP Proxy #2";
"Int. MX #1", "Int. MX #2" -> "IMAP Backend #1", "IMAP Backend #2";
"Int. MX #1", "Int. MX #2" -> "Ext. MX (out) #1", "Ext. MX (out) #2";
"Ext. MX (out) #1", "Ext. MX (out) #2" -> "External SMTP Servers";
"Web Proxy #1", "Web Proxy #2" -> "Webmail #1", "Webmail #2";
"Web Proxy #1", "Web Proxy #2" -> "ActiveSync #1", "ActiveSync #2";
"Webmail #1", "Webmail #2" -> "LDAP Proxy #1", "LDAP Proxy #2";
"Webmail #1", "Webmail #2" -> "Int. MX #1", "Int. MX #2";
"Webmail #1", "Webmail #2" -> "Memcached #1", "Memcached #2";
"Webmail #1", "Webmail #2" -> "DB Master #1", "DB Master #2";
"Webmail #1", "Webmail #2" -> "DB Slave #1", "DB Slave #2";
"Webmail #1", "Webmail #2" -> "IMAP Frontend #1", "IMAP Frontend #2";
"ActiveSync #1", "ActiveSync #2" -> "LDAP Proxy #1", "LDAP Proxy #2";
"ActiveSync #1", "ActiveSync #2" -> "Int. MX #1", "Int. MX #2";
"ActiveSync #1", "ActiveSync #2" -> "Memcached #1", "Memcached #2";
"ActiveSync #1", "ActiveSync #2" -> "DB Master #1", "DB Master #2";
"ActiveSync #1", "ActiveSync #2" -> "DB Slave #1", "DB Slave #2";
"ActiveSync #1", "ActiveSync #2" -> "IMAP Frontend #1", "IMAP Frontend #2";
"IMAP Proxy #1", "IMAP Proxy #2" -> "IMAP Frontend #1", "IMAP Frontend #2" [dir=none];
"IMAP Frontend #1", "IMAP Frontend #2" -> "IMAP Backend #1", "IMAP Backend #2" [dir=none];
"Client (External)" -> "Ext. MX (in) #1", "Ext. MX (in) #2";
"Client (External)" -> "IMAP Proxy #1", "IMAP Proxy #2";
"Client (External)" -> "Web Asset #1", "Web Asset #2";
"Client (External)" -> "Web Proxy #1", "Web Proxy #2";
"Client (Internal)" -> "IMAP Frontend #1", "IMAP Frontend #2";
"Client (Internal)" -> "Int. MX #1", "Int. MX #2";
"Client (Internal)" -> "Web Asset #1", "Web Asset #2";
"Client (Internal)" -> "Web Proxy #1", "Web Proxy #2";
}](../_images/graphviz-c042b75e30894cfa36c13665a3b52b7edf5b971d.png)
Scaling LDAP Servers¶
In a minimally distributed deployment topology, all components speak to a single LDAP server.
![digraph {
rankdir = LR;
splines = true;
overlab = prism;
edge [color=gray50, fontname=Calibri, fontsize=11];
node [style=filled, shape=record, fontname=Calibri, fontsize=11];
"LDAP Server" -> "MTA", "MUA", "IMAP" [dir=back];
}](../_images/graphviz-575505bc6026229951922331552253b58fc7e577.png)
This can be extended by replicating LDAP with the introduction of one or more replication slaves dedicated to read-only operations:
![digraph {
rankdir = LR;
splines = true;
overlab = prism;
edge [color=gray50, fontname=Calibri, fontsize=11];
node [style=filled, shape=record, fontname=Calibri, fontsize=11];
"LDAP Write Master(s)" -> "LDAP Read Slave(s)" [dir=one];
"LDAP Read Slave(s)" -> "MTA", "MUA", "IMAP" [dir=back];
}](../_images/graphviz-799264566a8e21da16958e4357dc1fe2efc9fdd4.png)
And extended yet even further by the introduction of (caching) proxies:
![digraph {
rankdir = LR;
splines = true;
overlab = prism;
edge [color=gray50, fontname=Calibri, fontsize=11];
node [style=filled, shape=record, fontname=Calibri, fontsize=11];
"LDAP Write Master(s)" -> "LDAP Read Slave(s)" [dir=one];
"LDAP Read Slave(s)" -> "LDAP Proxies" [dir=back];
"LDAP Proxies" -> "MTA", "MUA", "IMAP" [dir=back];
}](../_images/graphviz-9165c2589821d47e79523838cd9b4e86ec75facd.png)
Scaling Web Services¶
A single web server can not handle the requests of too many users, and even if it could, it would not be high-available. When web services are distributed, especially where it concerns a single web application being distributed, things such as sessions and also some caches must be stored outside the web server node.
This is to prevent a loss of session validity when users turn (out) to hit another web server node for subsequent requests as part of their existing session, and should be taken in to account even when “sticky” load-balancing is employed.
Since this session storage must be available to all web server nodes participating in serving an application, it makes sense to provide this session storage over the network.
To do so in a SQL database however tends to put an unfair burden on the SQL infrastructure, especially when replication is involved.
You could simply use memcached for the session storage, but this moves the single point of failure just one step further – namely should the memcached server, fail, sessions are lost.
To reduce the number of sessions lost, or to increase storage capacity horizontally, one can supply multiple memcached servers to the session storage driver, which will be used as a pool – the sessions would be spread throughout the pool. Loss of a single memcached server is then limits to only a subset of the sessions.
A much improved scenario is assisted by replicated memcached. Pairs of memcached servers replicate with one another so that either can fail.
Role(s) for Mail Exchangers¶
Backend Mail Exchanger
A backend mail exchanger is also a Cyrus IMAP backend.
Internal mail exchangers use LDAP to look up which Cyrus IMAP backend server system the user’s mailbox or shared folder resides on. They then relay the message to the backend mail exchanger for final delivery, using SMTP.
Kolab Groupware uses SMTP by default, while using networked LMTP is another option.
Todo
We probably need to explain why we choose to use SMTP rather than LMTP.
State something about pre-authorizing LMTP, it happening over the network, murder topologies and LMTP proxying, the use of LDAP holding the mailHost attribute, accounting, etc.
Internal Mail Exchanger
Responsible for internal routing of email, including;
Relay outbound messages to the external mail exchanger(s),
Relay inbound messages to the appropriate backend mail exchanger(s),
Relay messages to appropriate third party groupware or services,
Expansion of distribution groups into its individual member recipient addresses,
Optionally responsible for the application of anti-virus.
Note
It is probably the responsibility of the external mail exchanger(s) to scan for spam messages. The internal mail exchanger(s) receive mail from the internal network, and from the external mail exchanger(s).
External Mail Exchanger
Responsible for external mail routing
Splitting External & Internal Mail Exchangers¶
The following diagram illustrates the split of roles for mail exchangers, and their involvement in a deployment.
![digraph {
"Internet" -> "External Mail Exchanger" [dir=both];
"External Mail Exchanger" -> "Internal Mail Exchanger" [dir=both];
"Internal Mail Exchanger" -> "Backend Mail Exchanger" [dir=both];
"MUA" -> "Internal Mail Exchanger";
}](../_images/graphviz-ebafcfa130b01e29778dcd59ab1d2cde0a005ddf.png)
In this deployment scenario, each of the roles can be fulfilled by one or more servers. To illustrate, here’s a diagram for a deployment scenario that expects to be hammered by probably illegitimate or unsollicited mail, and does not expect that much traffic internally:
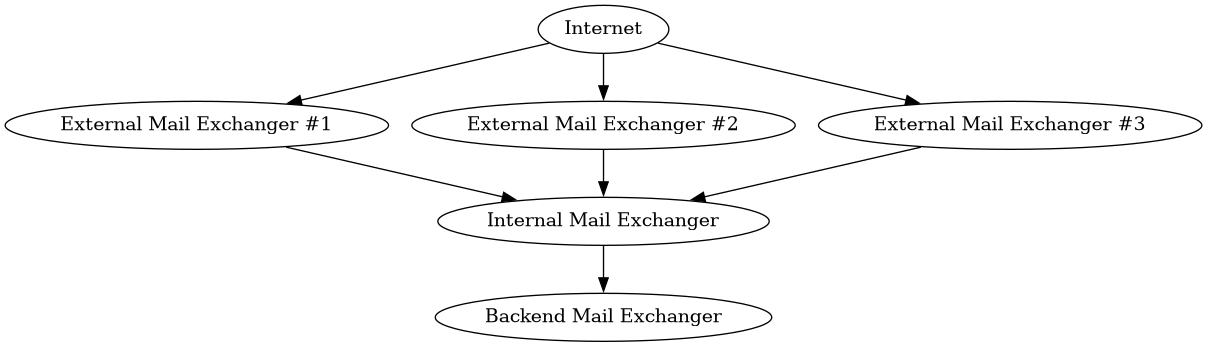
Responsibilities of an External Mail Exchanger¶
The responsibilities of an external mail exchanger typically include at least:
Check whether the message is supposed to be delivered within the local environment - at least at the domain level.
Check whether the sender is trustworthy.
Filtering for spam.
Scanning for virusses.
In addition, the external mail exchanger may be made responsible for an initial check on whether the intended recipient is a valid local recipient. We recommend considering, however:
An external mail exchanger is typically positioned in a perimeter network.
Checking the validity of recipient addresses in the perimeter network implies a (fractional) copy of the LDAP directory tree is available to the external mail exchanger.
Allowing nodes in a perimiter network to directly query internal LDAP servers is an attack vector, and you should thus consider creating a slave replica LDAP server in the perimeter network.
You should consider making this replica a purposeful fractional replica, as to make available in the perimeter network the absolute least amount of information necessary for the external mail exchanger.
Use different bind credentials on the external mail exchanger, and make sure no internal service accounts are replicated.
You should, subsequently, also consider removing unnecessary indexes from the LDAP databases, and reduce the indexes for recipient mail address attributes (mail, for example, has an index for presence, substring presence and equality, with the substring presence being unnecessary).
Balancing Client Connections to Services¶
Aside from a number of appliances to this purpose, one can implement load-balancing with implied high-availability if the Kolab Groupware functional components or roles are each installed on at least two systems.
Multiple functional components may be installed on a single system.
Caution
Most appliances, like this solution based on keepalived, will need the clients connected on failover or failback to reconnect to the new system to which the service IP address in use is attached.
Two LDAP servers are installed in multi-master replication mode:
Server #1 has a system IP address of 192.168.122.1.
Server #2 has a system IP address of 192.168.122.2.
Both systems run keepalived.
Server #1 is the designated master for the 192.168.122.3 service IP address (with priority 200 over 100), and
Server #2 is the designated master for the 192.168.122.4 service IP address (with priority 200 over 100).
The keepalived service has been configured to check the health of the local system’s LDAP service, and substract 101 from its priority should its health check fail.
In a normal situation, Server #1 holds the .3 service IP address, while Server #2 holds the .4 service IP address.
DNS for
example.orghas been configured to hold two IN A records forldap.example.org:192.168.122.3
192.168.122.4
The client system requests the IN A for
ldap.example.org:![digraph {
rankdir=LR;
"Client" -> "DNS Server" [label="IN A ldap.example.org"];
"DNS Server" -> "Client" [label="192.168.122.3, 192.168.122.4"];
}](../_images/graphviz-e35129801823b0289c689ac4da79b15b0a133549.png)
The client connects to one (semi-randomly selected) of the resulting IP addresses:
Which server this connection ends up with depends on the health of Server #1 and #2.
In a normal situation:

and:

Should Server #1 fail (its local LDAP service health check(s)):

and: